
Hyperspace V2.0: A Breakthrough in AI Search Performance 🚀

I’m excited to announce Hyperspace V2.0, introducing a major step forward in AI search infrastructure.
With this release, Hyperspace delivers a step-function leap in retrieval performance:
⚡ 10× faster search
📈 7.5× higher throughput
💰 6× more cost efficiency
These results set a new benchmark for what’s possible in real-world LLM, RAG, and agentic AI deployments - breaking through the glass ceiling that has constrained AI infrastructure for years.
Retrieval Has Become the Bottleneck in AI
Every LLM and AI agent depends on retrieval, which must run in real-time. Just as the human brain cannot think without memory, AI models cannot reason without timely, relevant context.
But today’s infrastructure was never built for this:
- CPUs crumble when real-time workloads require thousands of concurrent queries per second.
- GPUs excel at AI training and inference, but they are not designed for workloads like search, filtering, candidate generation, ranking or vector similarity.
- Databases and vector DBs (often Lucene-based) were optimized for observability and logging - not real-time, high-throughput AI queries.
This mismatch creates a glass ceiling in search performance:
- Latency spikes beyond real-time user experience which demands P95 < 200 ms.
- Throughput collapses and is fragile to surges in demand, especially in agentic workloads which require high parallelism.
- Costs skyrocket when scaling to billions of documents and high frequency queries.
The result: RAG pipelines break in production, and AI agents fail to act fully autonomously in real-time.
The Challenge of Performance in Real-World AI Search
Most search benchmarks are misleading. Systems may show strong results on synthetic workloads - but real-world queries are rarely simple.
- Complex queries: Our benchmarks were performed on workloads with dozens of terms, multi-stage filters, and complex business logic - not just simple nearest-neighbor lookups.
- Hybrid candidate generation: Efficient retrieval requires blending vector similarity with business logic while leveraging metadata filtering, sorting, and scoring - all at high concurrency.
- Trade-offs: Query complexity usually comes at the cost of performance. Optimizing both simultaneously is notoriously difficult.
This is why most systems collapse when complexity meets scale. Achieving low latency with real-world queries is the true test - and it’s where Hyperspace V2.0 stands apart.
Inside Hyperspace V2.0:
Real-time search engine powered by domain-specific computing, bringing a dedicated hardware-accelerated Search Processing Unit (SPU)
We didn’t just speed things up - we rebuilt the search engine as a highly parallelized multi-core chip with a fully optimized pipelined dataflow:
⚙️ Index Fetching in HBM
Headers are streamed directly from ultrafast HBM (high bandwidth memory). Hardware bound-checks skip blocks that can’t win before any postings are read.
⚙️ Roaring Bitmap in Hardware
Postings Lists use Roaring Bitmap containers, decoded by dedicated array/bitmap/run engines. Set ops run at line rate with no branching.
⚙️ Filter Logic Fabric
Bit-sliced attributes and list intersections are resolved in parallel logic, cutting candidate fan-out early.
⚙️ Multi-Core Superarchitecture
Dozens of supercores run concurrently, each saturating its slice of HBM. Throughput scales nearly linearly, up to the memory wall.
The result: massive throughput, exact results, and deterministic latency, built directly into silicon.
Real-World Benchmark: Hyperspace V2.0
We benchmarked Hyperspace V2.0 on real customer data in verticals such as financial services, recommendation, healthcare, fraud detection, and quant trading.
Benchmark setup:
- Dataset: 20 million multi-dimensional documents with hundreds of terms alongside 1536-dimensional vector embeddings.
- Use case: Real-time anomaly detection, RAG and agentic retrieval queries running at low latency and high throughput.
- Search functions:
- Candidate Generation - exact keyword search, range filters, boolean expressions (AND/OR/NOT) and full text search
- Lexical scoring - BM25 and TF/IDF ranking, boosting and user-defined score functions
- Vector search - semantic search capabilities over embeddings - HNSW
- Comparison: Running ‘apples-to-apples’ comparison between OpenSearch, running on CPUs, vs. Hyperspace Search Processing Unit (SPU).
Hardware Setup:
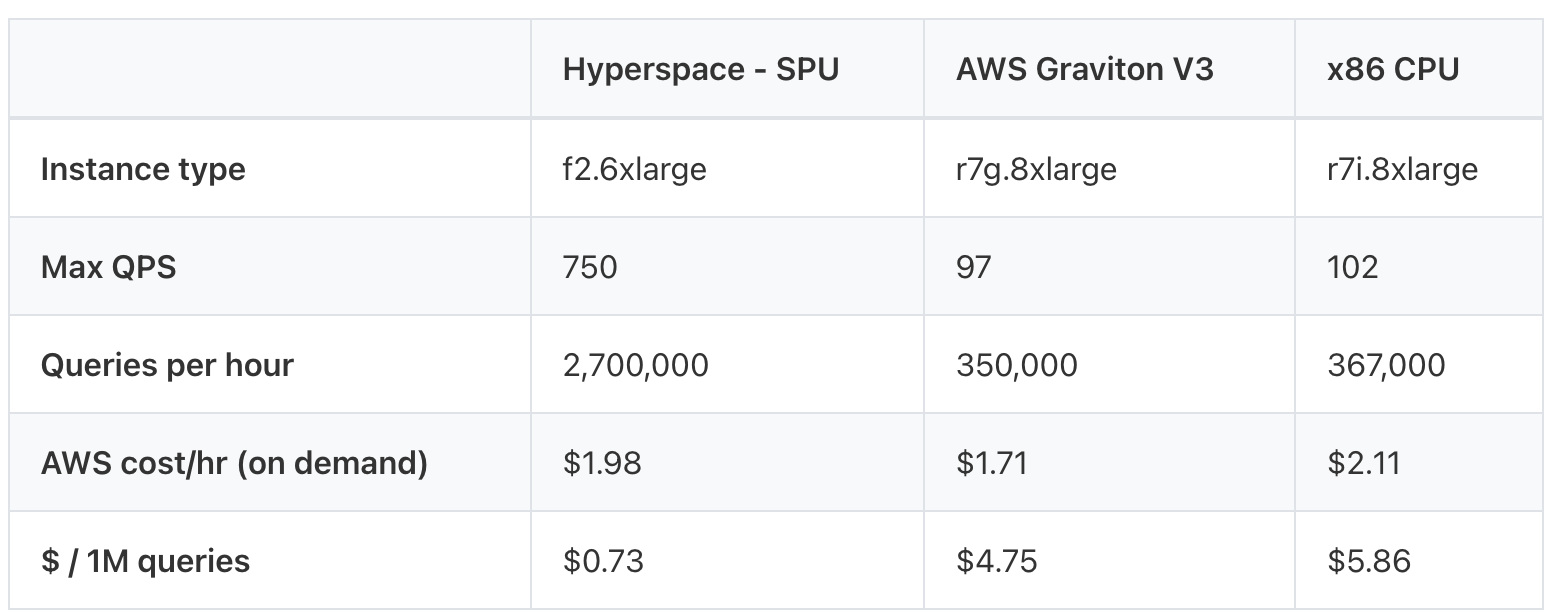
- Hyperspace SPU - AWS f2.6xlarge (AMD Virtex UltraScale+ HBM VU47P).
- Graviton V3 - AWS r7g.8xlarge (16 vCPUs, 64 GiB DDR5 RAM).
- x86 CPU - AWS r7i.8xlarge (4th-Gen Intel Xeon).
*We compared against CPU-based search systems (OpenSearch). GPUs were excluded - while they excel at training and inference, they are not designed for retrieval workloads such as filtering, candidate generation, or ranking.
Results
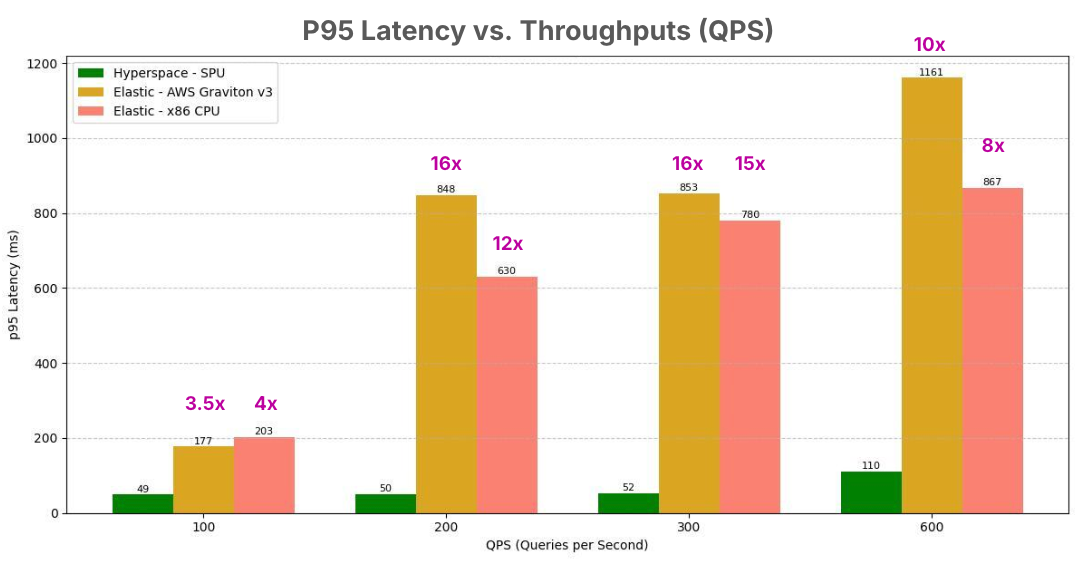
10× Faster at Scale
Hyperspace SPU sustains real-time latency under high QPS, running more than 10× faster than CPU-based systems.
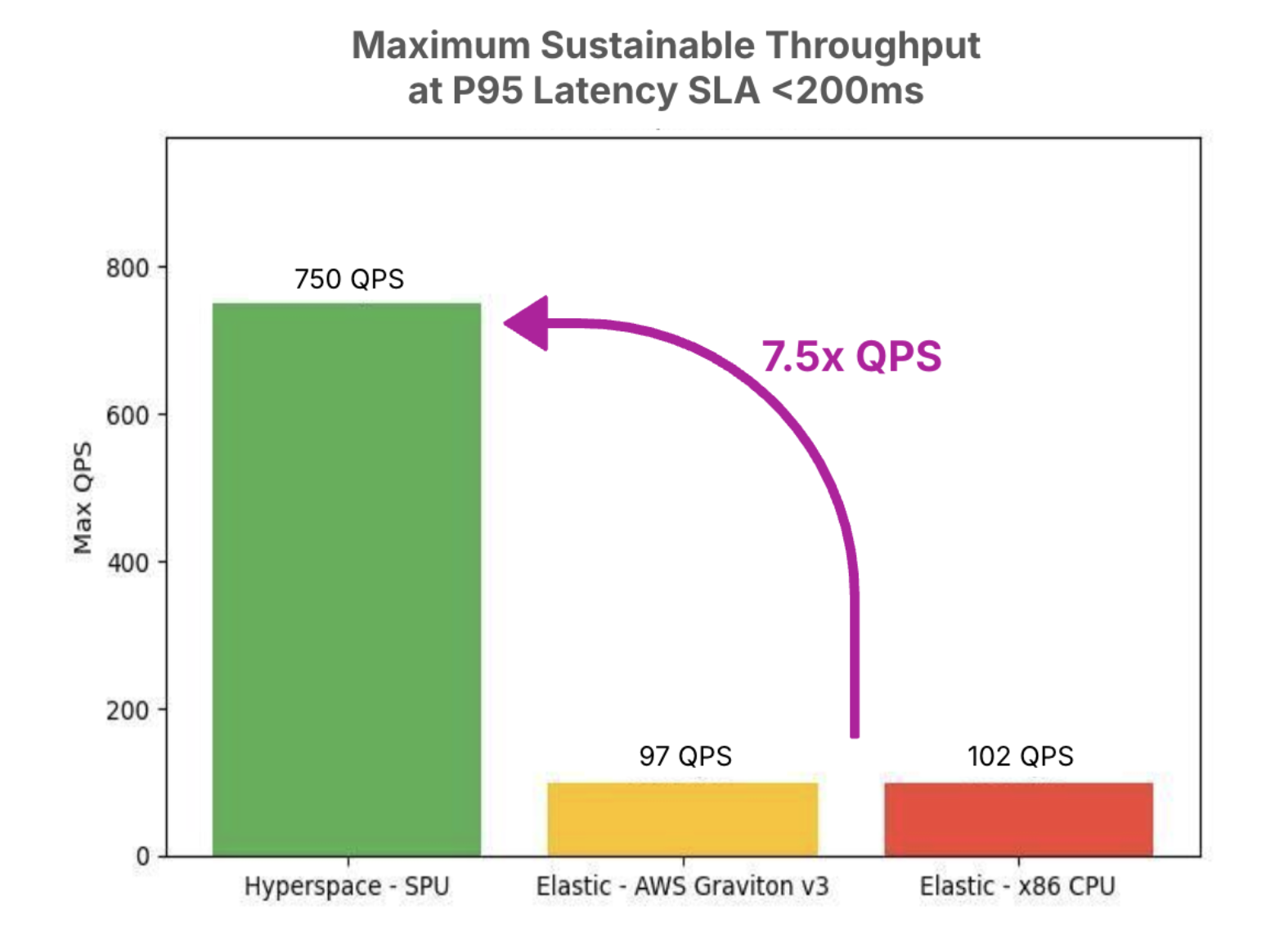
7.5× Higher Throughput
At a real-time SLA of P95 <200ms, Hyperspace delivers 7.5× higher throughput compared to OpenSearch on CPUs.
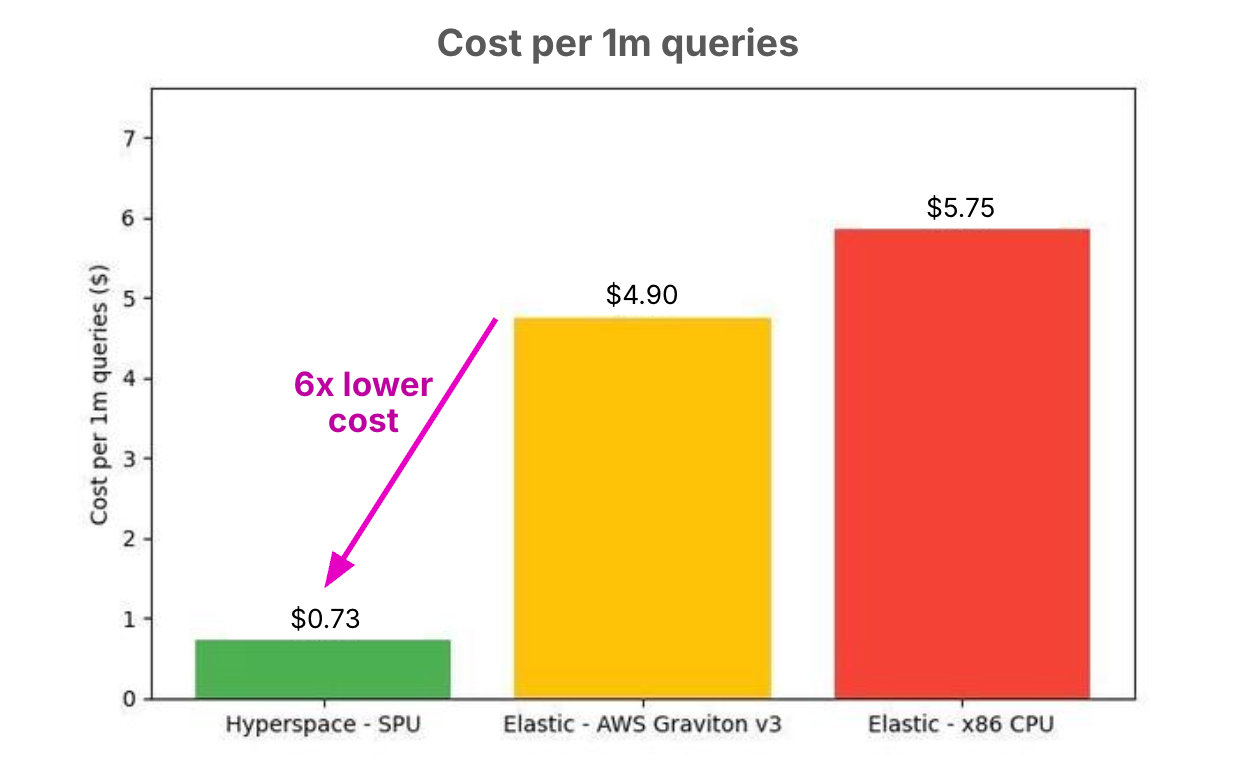
6× Cost Efficiency
Hyperspace reduces the cost of 1 million queries from $4.90 → $0.73, a 6× improvement in efficiency.
Why This Matters
These results are not synthetic. They come from production-grade, highly complex queries that mirror the reality of real-time AI workloads.
- In quant trading, milliseconds = millions.
- In fraud detection, catching anomalies in real-time is the difference between prevention and loss.
- In agentic AI, concurrency is the enabler of autonomy.
With V2.0, Hyperspace shows that retrieval can finally match the scale and complexity of real-world AI.
The Future of AI Search
This breakthrough is not just an optimization - it’s the beginning of a new infrastructure layer.
The Hyperspace SPU for search and retrieval is to AI memory what GPUs are to AI training and inference: a purpose-built compute engine that redefines what’s possible.
- Faster
- More concurrent
- More cost-efficient at scale
Search is the new AI compute. And with Hyperspace V2.0, the foundation is here.
Try It Yourself
👉 Hyperspace V2.0 is live on AWS Marketplace.
Run it on your own data, validate the benchmarks, and share the results you get. ⚡️
Sign up for an early access - https://www.hyper-space.io/contact




.png)





Experience the power
of hyper search today.
Learn why developers are switching from legacy software to domain specific computing power.